
Choosing between MySQL vs PostgreSQL vs SQL Server
The choice between SQL and non-SQL databases usually boils down to differences in the structure. However, when we are looking into several SQL solutions, the criteria are a lot more distorted. Now will consider the aspects more precisely and analyze the underlying functionality. We’ll be taking a look at the three most popular relational databases: MySQL vs Postgresql vs SQL server.

To help you, we have collected advice from our database developers, re-went through manuals, and even looked up official in-depth guides. We do tend to have our personal preferences, but in this guide, we will put them aside in favor of objective comparison.
MySQL
MySQL happens to be one of the most popular databases, according to DB Engines Ranking. It’s a definite leader among SQL solutions, used by Google, LinkedIn, Amazon, Netflix, Twitter, and others. MySQL popularity has been growing a lot because teams increasingly prefer open-source solutions instead of commercial ones.
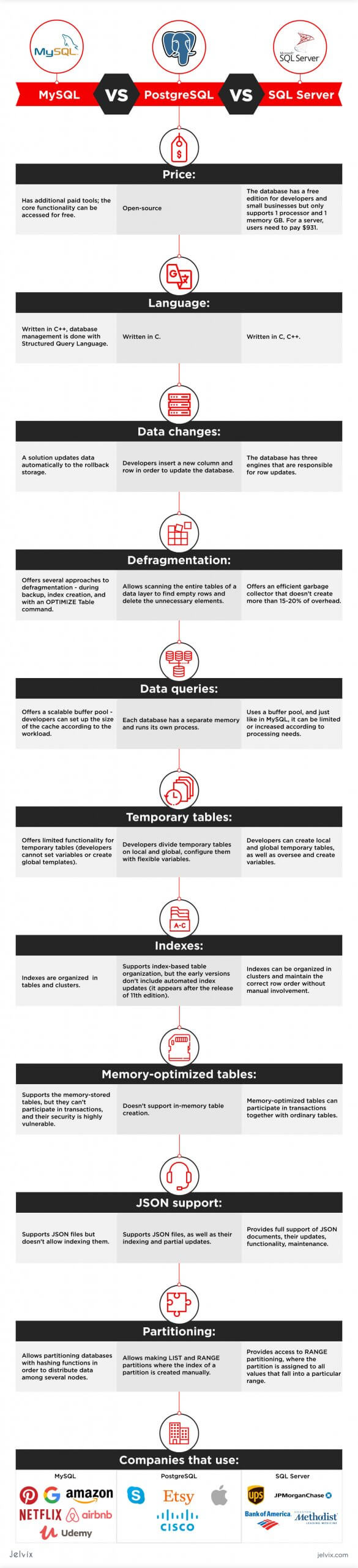
Price: the database solution is developed by Oracle and has additional paid tools; the core functionality can be accessed for free.
Language: MySQL is written in C++; database management is done with Structured Query Language.
Read our comparison of MongoDB vs MySQL to make the right choice of a database solution.
PostgreSQL
A tried-and-proven relational database that is known for supporting a lot of data types, intuitive storage of schemaless data, and rich functionality. Some developers go even as far as to claim that it’s the most advanced open-source database on the market. We wouldn’t go that far, but it’s definitely a highly universal solution.
Price: open-source
Language: C
SQL Server
Unlike Postgresql vs MySQL, SQL Server is a commercial solution. It’s preferred by companies who are dealing with large traffic workloads on a regular basis. It’s also considered to be one of the most compatible systems with Windows services.
The SQL Server infrastructure includes a lot of additional tools, like reporting services, integration systems, and analytics. For companies that manage multiple teams, these tools make a big difference in day-to-day work.
Price: the database has a free edition for developers and small businesses but only supports 1 processor, 1GB of maximum memory used by the database engine and 10GB maximum database size.
. For a server, users need to pay $931.
Side-by-side Comparison of SQL Tools
In this comparison, we’ll take a look at the functionality of the three most popular SQL databases, examine their use cases, respective advantages, and disadvantages. Firstly, we’ll start by exploring the in-depth functionality.
Data Changes
Here we evaluate the ease that the data can be modified with and the database defragmented. The key priority is the systems’ flexibility, security, and usability.
Row updates
This criterion refers to the algorithms that a database uses to update its contents, speed, and efficiency.
In the MySQL case, a solution updates data automatically to the rollback storage. If something goes wrong, developers can always go back to the previous version.
PostgreSQL: developers insert a new column and row in order to update the database. All updated rows have unique IDs. This multiplies the number of columns and rows and increases the size of the database, but in turn, developers benefit from higher readability.
SQL Server: the database has three engines that are responsible for row updates. The ROW Store handles the information on all previous row updates, IDs, and modified content. The in-memory engine allows analyzing the quality of an updated database with a garbage collector. The column-store database lets store updates in columns, like in column-driven databases.

Among these three, SQL Server offers perhaps the most flexibility and efficiency, because it allows monitoring updated rows and columns, collecting errors, and automating the process. The difference between SQL Server and MySQL and Postgresql lies mainly in customizing the positions – SQL Server offers a lot more than others.
Defragmentation
When developers update different parts of an SQL database, the changes occur at different points of the systems and can be hard to read, track, and manage. Therefore, maintenance should include defragmentation – the process of unifying the updated database by assigning indexes, revisiting the structure, and creating new pages. The database frees up the disk space that is not used properly so that a database can run faster.
MySQL offers several approaches to defragmentation – during backup, index creation, and with an OPTIMIZE Table command. Without going into much detail, we’ll just say that having that many options for table maintenance is convenient for developers, and it surely saves a lot of time.
PostgreSQL allows scanning the entire tables of a data layer to find empty rows and delete the unnecessary elements. By doing so, the system frees up the disk space. However, the method requires a lot of CPU and can affect the application’s performance.
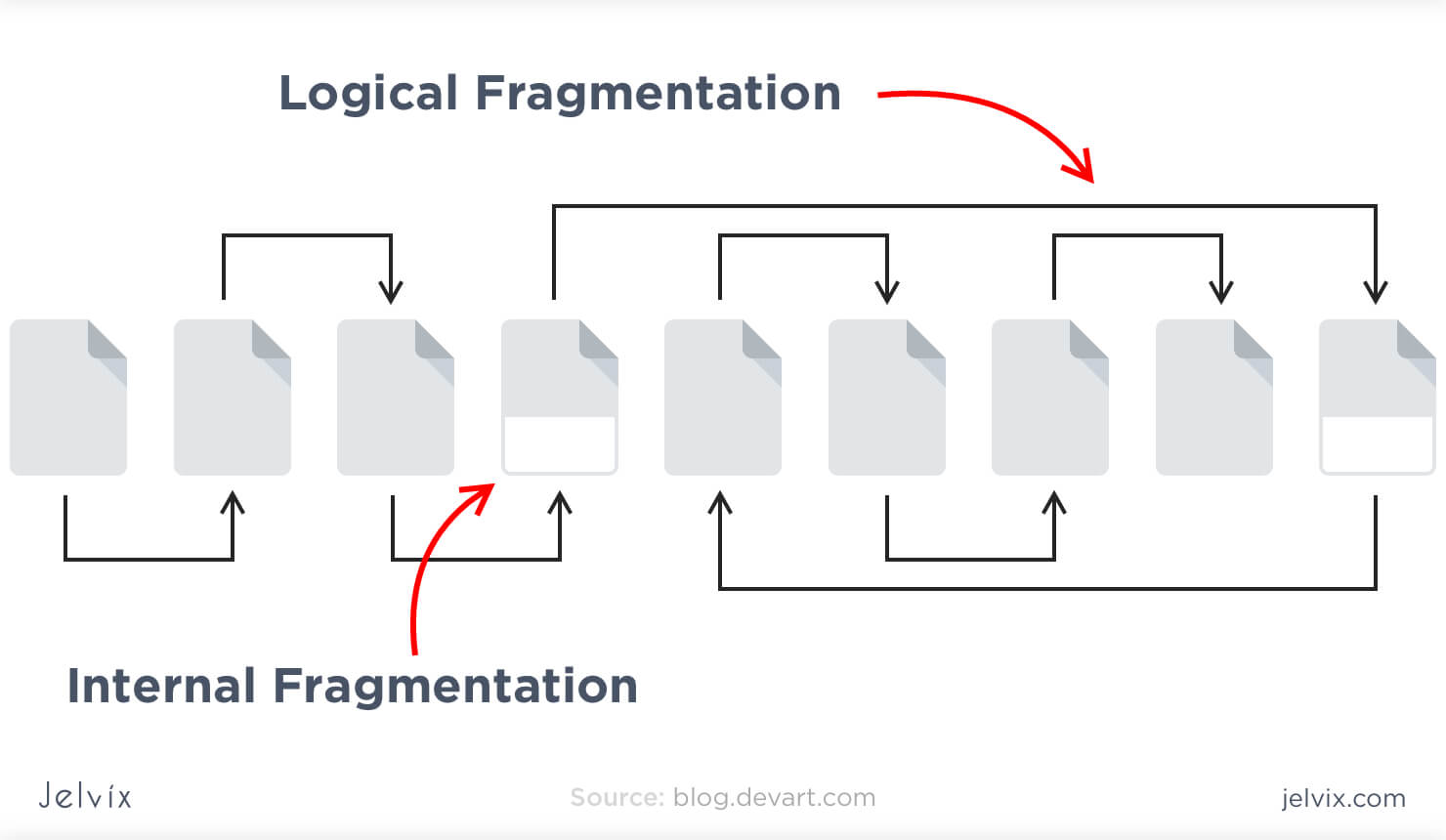
SQL Server offers an efficient garbage collector that doesn’t create more than 15-20% of overhead. Technically, developers can even run garbage collector on a continuous basis, because it’s that efficient.
Overall, MySQL and SQL Server offer more of defragmentation methods that Postgresql does. They consume less CPU and provide more flexible settings.
Data Queries
Here, we take a look at how the systems cache and process user requests, what approaches they take in storing data, and how developers can manage it.
Buffer Pool
Some systems call a buffer to pull cache, but regardless of terminology, our goal is to summarize the algorithms that systems use to process user queries and maintain connections.
MySQL offers a scalable buffer pool – developers can set up the size of the cache according to the workload. If the goal is to save CPU and storage space, developers can put strict benchmarks on their buffer pool. Moreover, MySQL allows dividing cache by segments to store different data types and maximize isolation.
PostgreSQL isolates processes even further than MySQL by treating them as a separate OS process. Each database has a separate memory and runs its own process. On the one hand, management and monitoring become a lot easier, but on the other, scaling multiple databases takes a lot of time and computing resources.
SQL Server also uses a buffer pool, and just like in MySQL, it can be limited or increased according to processing needs. All the work is done in a single pool, with no multiple pages, like in Postgresql.
If your priority is to save computing resources and storage, choose flexible solutions: the choice will be between MySQL vs SQL Server. However, if you prefer clear organization and long-term order, Postgre, with its isolated approach, might be a better fit.
Temporary Tables
Temporary tables allow storing intermediate results from complex procedures and branched business logic. If you need some information only to power the next process, it doesn’t make sense to store it in a regular table. Temporary tables improve database performance and organization by separating intermediary data from the essential information.
MySQL offers limited functionality for temporary tables. Developers cannot set variables or create global templates. The software even limits the number of times that a temporary table can be referred to – not more than once.
Postgresql offers a lot more functionality when it comes to temporary content. You divide temporary tables into local and global and configure them with flexible variables.
SQL Server also offers rich functionality for temporary table management. You can create local and global temporary tables, as well as oversee and create variables.
Temporary tables are essential for applications with complicated business logic. If your software runs a lot of complex processes, you will need to store multiple intermediary results. Having rich customization functionality will often be necessary throughout the development process.
Indexes
The way a database handles indexes is essential because they are used to locate data without searching for a particular row. Indexes can refer to multiple rows and columns. You can assign the same index to files, located in the different places in the database, and collect all these pieces with a single search.
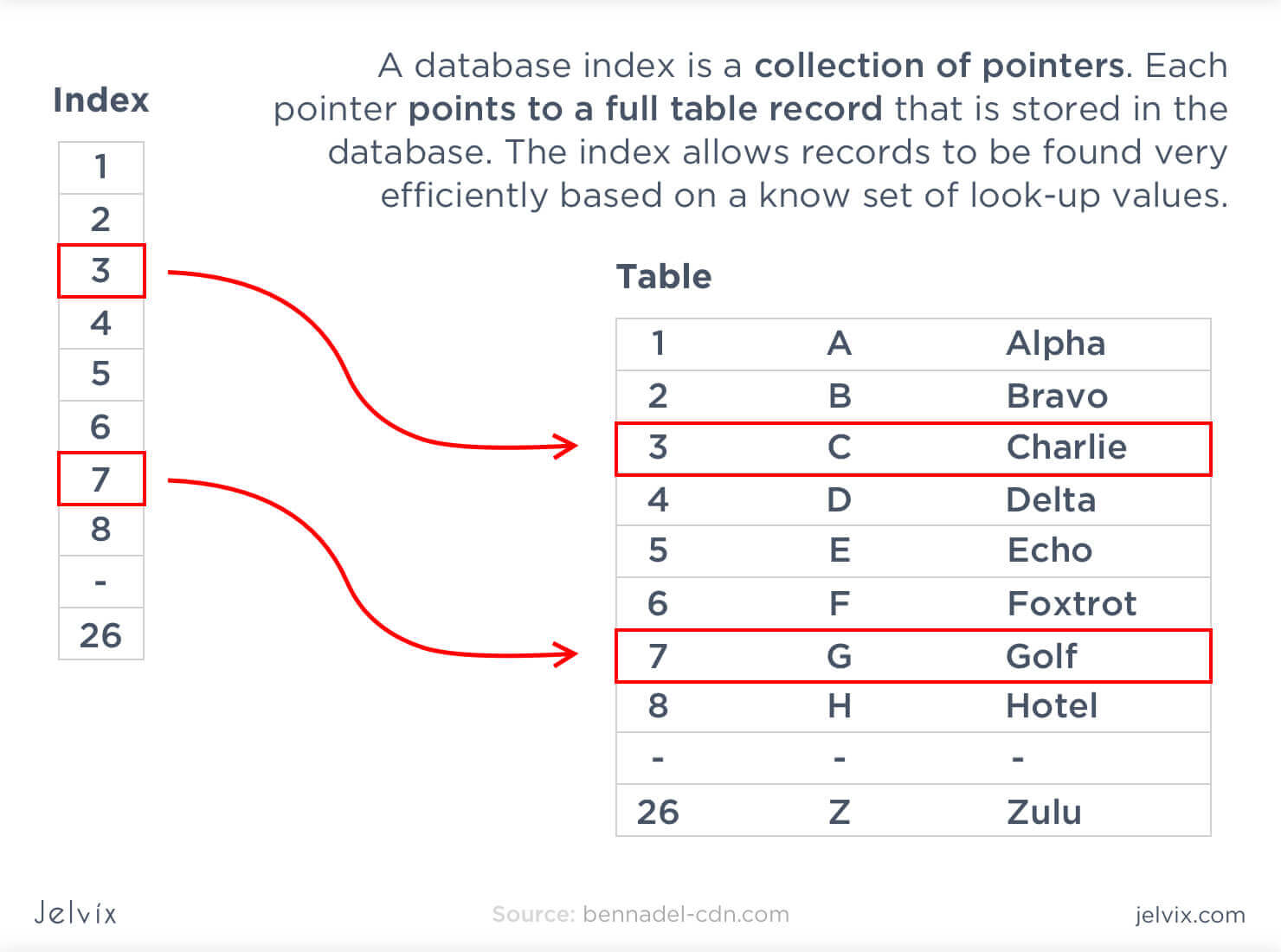
In this comparison, we evaluated the way indexes are created in every solution, the support of multiple-index searches, and multi-column indexes, as well as partial ones.
MySQL organized indexes in tables and clusters. Developers can automatically locate and update indexes in their databases. The search isn’t highly flexible – you can’t search for multiple indexes in a single query. MySQL supports multi-column indexes, allowing adding up to 16 columns.
Postgresql also supports index-based table organization, but the early versions don’t include automated index updates (which appear only after the 11th edition release). The solution also allows looking up many indexes in a single search, which means that you can find a lot of information. The multi-column settings are also more flexible than in MySQL – developers can include up to 32 columns.
SQL Server offers rich automated functionality for index management. They can organize in clusters and maintain the correct row order without manual involvement. The solution also supports multiple-index searches and partial indexes.
Having flexible index settings allows looking up information faster and organizing multiple data simultaneously.
Memory-Optimized Tables
Memory-optimized tables are mainly known as a SQL Server concept, but they also exist in other database management solutions. Such a table is stored in active memory and on the disk space in a simplified way. To increase the transaction speed, the application can simply access data directly on the disk, without blocking concurrent transactions. For processes that happen on a regular basis and usually require a lot of time, a memory-optimized table can be a solution to improve database performance.
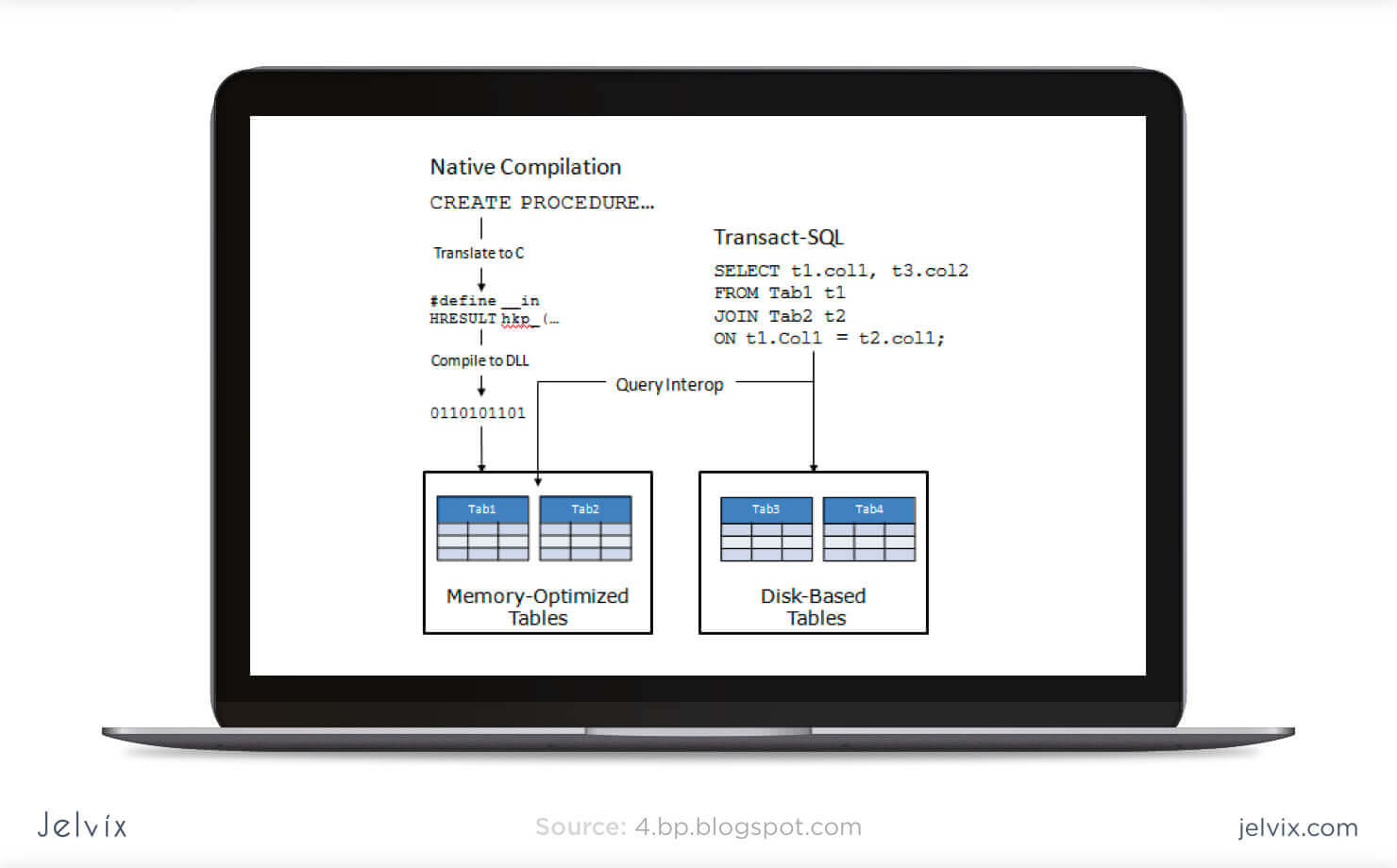
MySQL supports the memory-stored table, but it can’t participate in transactions, and its security is highly vulnerable. Such tables are used only for reading purposes and can simplify exclusively primitive operations. For now, MySQL doesn’t come close to making the most out of memory-optimized tables.
PostgreSQL doesn’t support in-memory database creation.
SQL Server uses an optimistic strategy to handle memory-optimized tables, which means they can participate in transactions along with ordinary tables. Memory-based transactions are faster than regular ones, and this allows a drastic increase in application speed.
As expected, memory-optimized tables are best set up in MySQL – it’s basically their native approach. It’s not an essential database feature, but still, a good way to improve performance.
JSON Support
The use of JSON files allows developers to store non-numeric data and achieve faster performance. JSON documents don’t have to be parsed, which contributes to much higher processing speed. They are easily readable and accessible, which is why JSON support simplifies maintenance. JSON files are mostly used in non-relational databases, but lately, SQL solutions have supported this format as well.
MySQL supports JSON files but doesn’t allow indexing them. Overall, the functionality for JSON files in MySQL is very limited, and developers mostly prefer using classical strings. Similarly to non-relational databases, MySQL also allows working with geospatial data, although handling it isn’t quite as intuitive.
Postgresql supports JSON files, as well as their indexing and partial updates. The database supports even more additional data than MySQL. Users can upload user-defined types, geospatial data, create multi-dimensional arrays, and a lot more.
SQL Server also provides full support of JSON documents, their updates, functionality, and maintenance. It has a lot of additional features for GPS data, user-defined types, hierarchical information, etc.
Overall, all three solutions are pretty universal and offer a lot of functionality for non-standard data types. MySQL, however, puts multiple limitations for JSON files, but other than that, it’s highly compatible with advanced data.
Replication and Sharding
When the application grows, a single server can no longer accommodate all the workload. Navigating single storage becomes complicated, and developers prefer to migrate to different ones or, at least, create partitions. The process of partitioning is the creation of many compartments for data in the single process.
Partitioning
Replacing is easier in NoSQL databases because they support horizontal scaling rather than vertical – increasing the number of locations rather than the size of a single one. Still, it’s possible to distribute data among different compartments even in SQL solutions, even if it’s slightly less efficient.
MySQL allows partitioning databases with hashing functions in order to distribute data among several nodes. Developers can generate a specific partition key that will define the data location. Hashing permits avoiding bottlenecks and simplifying maintenance.
Postgresql allows making LIST and RANGE partitions where the index of a partition is created manually. Developers need to identify children and parent column before assigning a partition for them.
SQL Server also provides access to RANGE partitioning, where the partition is assigned to all values that fall into a particular range. If the data lies within the threshold, it will be moved to the partition.
Ecosystem
The database ecosystem is important because it defines the frequency of updates, the availability of learning resources, the demand on the market, and the tool’s long-term legacy.
MySQL Ecosystem
MySQL is a part of the Oracle ecosystem. It’s the biggest SQL database on the market with a large open-source community. Developers can either purchase commercial add-ons, developed by the Oracle team or use freeware installations. You will easily find tools for database management, monitoring, optimization, and learning. The database itself is easy to install – all you have to do is pretty much download the installer.
MySQL has been a reliable database solution for 25 years, and statistics don’t pinpoint at any sights of its decline. It looks like MySQL will keep holding a leading position not only among SQL tools but also among all the databases in general.
Postgresql Ecosystem
The Postgresql community offers a lot of tools for software scaling and optimization. You can find add-ons by your industry – take a look at the full list on the official page. The integrations allow developers to perform clustering, integrating AI, collaborating, tracking issues, improving object mapping, and cover many other essential features.
Some developers point out that Postgresql’s installation process is slightly complicated – you can take a look at its official tutorial. Unlike MySQL, which can run right away, Postgresql requires additional installations.
SQL Server Ecosystem
SQL Server is highly compatible with Windows and all Microsoft OS and tools. If you are working with Windows, SQL server is definitely the best option on the market. Users of the database receive access to many additional instruments that cover server monitoring (Navicat Monitor), data analysis, parsing (SQL Parser), and safety management software (DBHawk).
SQL Server ecosystem is oriented towards large infrastructures. It’s more expensive than open-source competitors, but at the end of the day, users get access to frequently updated official ecosystem and active customer support.
What is the difference between SQL and MySQL? MySQL is an open-source database, whereas SQL Server is a commercial one. MySQL is more popular, but SQL Server comes close.
Popularity
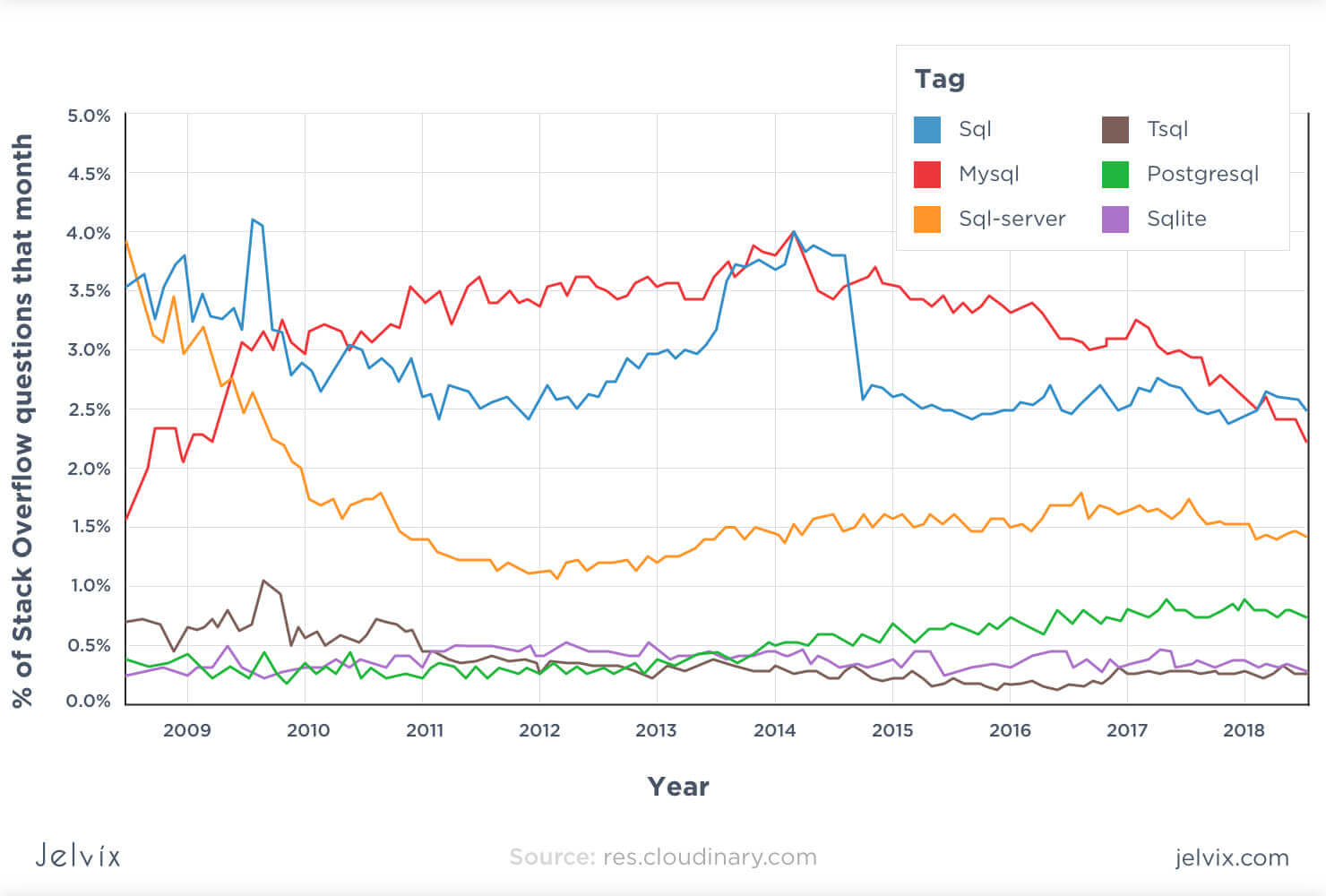
For a start, we analyzed the DB Engines ratings of every compared engine. The leader is MySQL, with second place as the most popular database and second most popular relational solution. SQL Server takes third place, while PostgreSQL is ranked fourth.
The statistics by Statista shows the same tendency. MySQL is ranked second, leaving the leading position to Oracle, the most popular DBMS today. SQL Server follows with a slim difference, whereas Postgresql, which comes right after, is a lot less recognized.
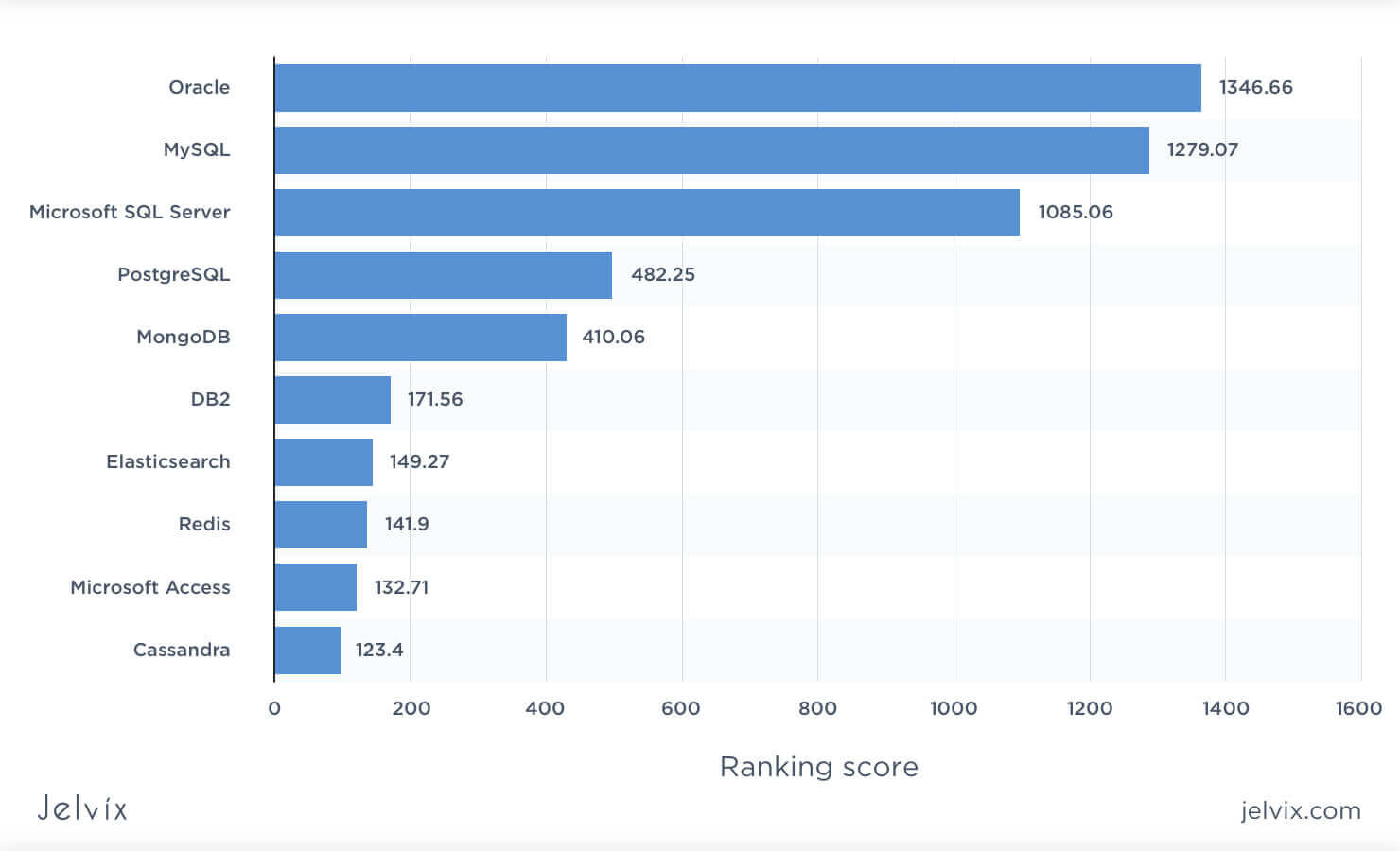
MySQL, therefore, is the most demanded database on the market, which means finding competent teams, learning resources, reusable libraries, and ready add-ons will be easy. So, if you are choosing between SQL Server vs MySQL in terms of market trends, the latter is a better choice.
Companies using MySQL
- Udemy
- Netflix
- Airbnb
- Amazon
MySQL is used widely by big corporations and governmental organizations. Over the last 25 years, the solution has built a reputation of a reliable database management solution, and as time shows, it’s indeed capable of supporting long-running projects.
Companies that use PostgreSQL
- Apple
- Skype
- Cisco
- Etsy
Postgre is known for its intuitive functionality and versatile security settings. This is why its main use cases are governmental platforms, messenger applications, video chats, and e-commerce platforms.
Companies using SQL Server
- JPMorganChase
- Bank of America
- UPS
- Houston Methodist
SQL Server is a go-to choice for large enterprises that have vast business logic and handle multiple applications simultaneously. Teams that prioritize efficiency and reliability over scalability and costs typically choose this database. It’s a common option for “traditional” industries – finances, security, manufacturing, and others.
Conclusion
The choice between the three most popular databases ultimately boils down to the comparison of the functionality, use cases, and ecosystems. Companies that prioritize flexibility, cost-efficiency, and innovation usually choose open-source solutions. They can be integrated with multiple free add-ons, have active user communities, and are continuously updated.
For corporations that prefer traditional commercial solutions, software like SQL Server backed up by a big corporation and compatible with an extensive infrastructure, is a better bet. They have access to constant technical support, personalized assistance, and professional management tools.
If you are considering a database for your project, getting a team of experts who will help you define the criteria and narrow down the options is probably the best idea. You can always get in touch with our database developers – we will create a tech stack for your product and share our development experience.